一、前言
Java集合作为Java基础最重要的一部分之一,也是深受面试官青睐的考点之一。尽管Java集合如此重要,楼主还是没有下功夫学习(内疚三分钟,hhh)。在经历了无数次的血虐之后,楼主终于痛定思痛,决定好好深入学习一番。ps:我还就不信了,小小的集合能难的倒我聪明伶俐又帅气的小马哥,hhh,学习之前先给自己打打气嘛~~~
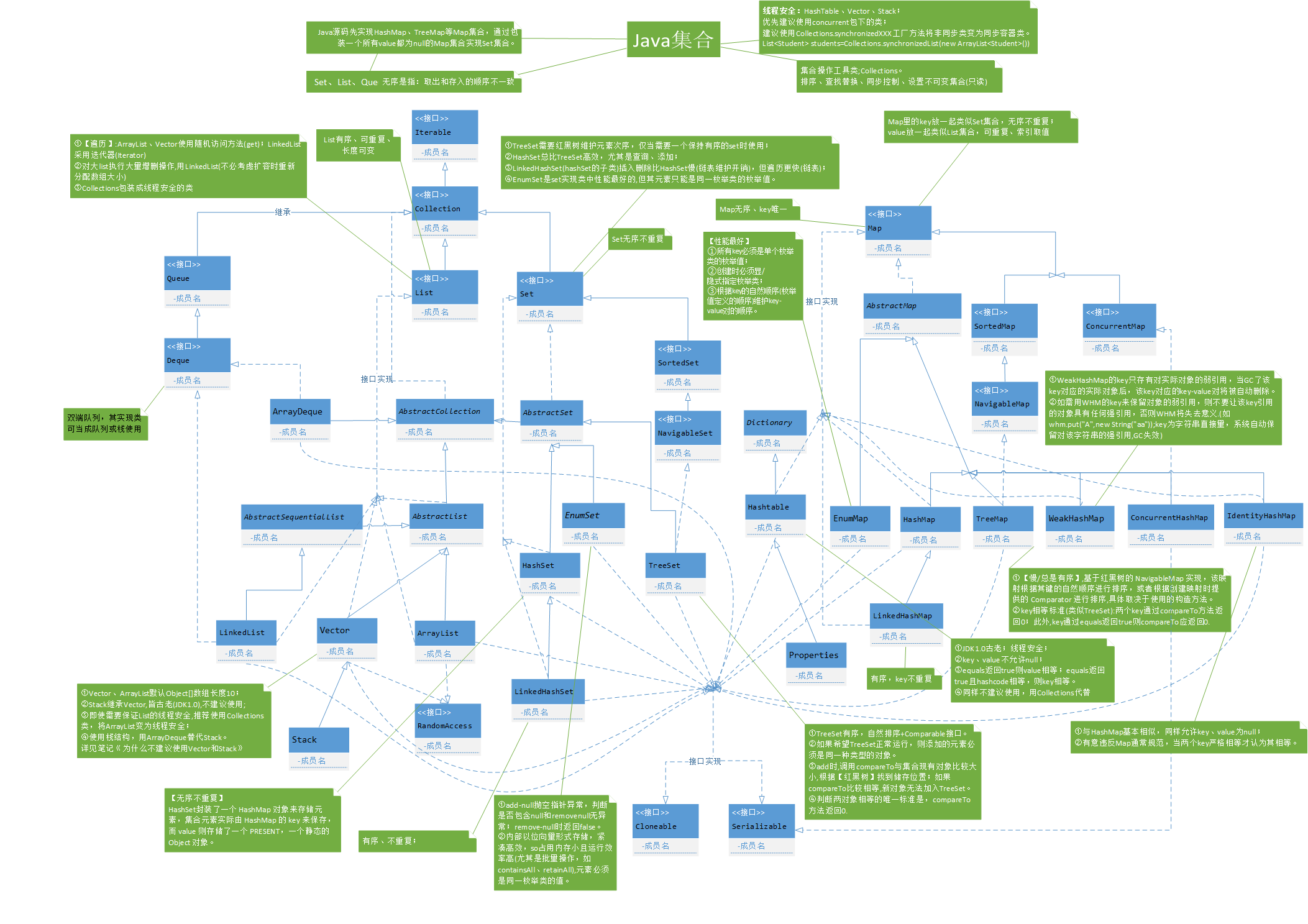
二、Java集合框架图
废话不多说,学习之前,咱们先来对Java的集合体系有个整体的把握。省得面试官直接问你:“讲一下Java的集合”。你不知从何说起。(诅咒这样的面试官三分钟,Java集合东西那么多,你让我说什么嘛。对于不善表达、爱敲代码的我来说,简直是送命一问,ps:掉下难过的眼泪)
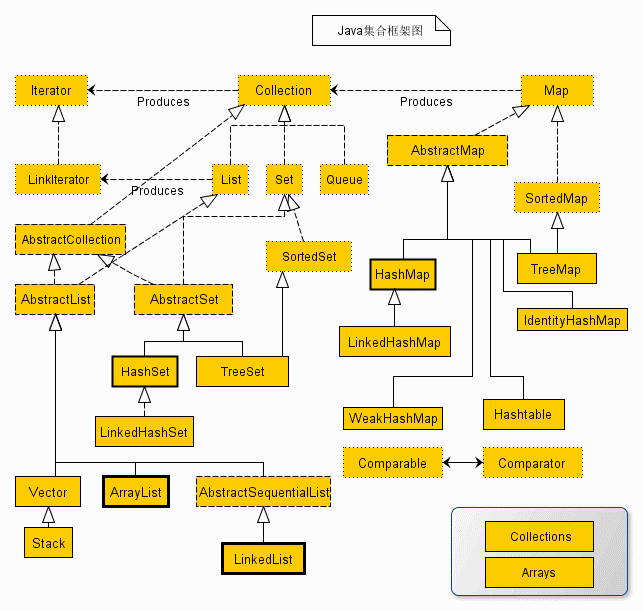
详细版(看不清你就把浏览器页面放大点嘛,这也不能怪我。好吧,放大你也看不清):
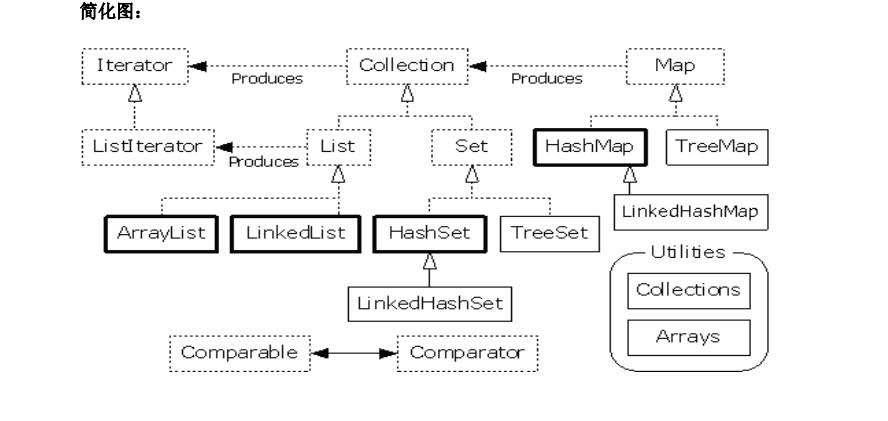
简化版(说实在的,面试常考的也就这些):
三、集合基础知识点
对于不太熟悉集合和像我这样水平不是很强的小伙伴(谦虚一下嘛,我还是很强的。heiheihei),不建议直接刚源码。虽然集合源码必看,那咱们后面再研究嘛,谁一口也吃不了一个胖子(胖子:??我惹你了?),掌握了基本原理,再看源码,相对来说会容易很多。
接下来,咱们就以简化图为大纲,来开始我们的Java集合之旅吧。
迭代器
Iterator接口
简介:Iterator则主要用于遍历集合的元素。又叫迭代器。
方法简介:
1 | boolean hasNext();//如果被迭代的集合元素还有没遍历,则返回true。 |
注意点:
- Iterator仅用于遍历集合,如果需要创建Iterator对象,则必须有一个被迭代的集合。没有集合和Iterator仿佛无本之木,没有存在的意义。
- 当使用Iterator对集合元素进行迭代时,Iterator并不是把集合元素本身传给了迭代变量,而是把集合元素的值传给了迭代变量,所以修改迭代变量的值对集合元素本身没有影响。
- 当使用Iterator来迭代访问Collection集合元素时,Collection集合里的元素不能被修改,只能通过remove方法删除上次next方法返回的集合元素才可以,否则报java.util.ConcurrentModificationException异常。
- Iterator迭代器采用的是快速失败(fail-fast)机制,一旦在迭代过程中检测到该集合已经被修改(通常是其他线程进行修改),程序将报java.util.ConcurrentModificationException异常。而不是显示修改后的结果,这样可以避免共享资源而引发的问题。
ListIterator接口
简介:迭代器,用于对List、ArrayList、LinkedList和Vector的迭代。
方法简介:
1 | add(E e);//将指定的元素插入列表,插入位置为迭代器当前位置之前 |
与Iterator比较:
一.相同点
都是迭代器,当需要对集合中元素进行遍历不需要干涉其遍历过程时,这两种迭代器都可以使用。
二.不同点
1.使用范围不同,Iterator可以应用于所有的集合,Set、List和Map和这些集合的子类型。而ListIterator只能用于List及其子类型。
2.ListIterator有add方法,可以向List中添加对象,而Iterator不能。
3.ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序向后遍历,但是ListIterator有hasPrevious()和previous()方法,可以实现逆向(顺序向前)遍历。Iterator不可以。
4.ListIterator可以定位当前索引的位置,nextIndex()和previousIndex()可以实现。Iterator没有此功能。
5.都可实现删除操作,但是ListIterator可以实现对象的修改,set()方法可以实现。Iterator仅能遍历,不能修改。
好了,咱们的迭代器之旅就先告一段落了,接下来咱们开始集合中最为重要且最为庞大的Collection之旅
Collection
collection接口继承树
Collection接口
简介(引用百度的解释,虽然我觉得是废话,但这不没话说了了嘛):Collection是最基本的集合接口,一个Collection代表一组Object,即Collection的元素(Elements)。Collection接口是Set、List和Queue接口(Java5新增,后面也要学习下)的父接口。
方法简介:
1 | add(Object o);//增加元素 |
List接口
介绍:List接口为Collection直接接口。List所代表的是有序的Collection,即它用某种特定的插入顺序来维护元素顺序。用户可以对列表中每个元素的插入位置进行精确地控制,同时可以根据元素的整数索引(在列表中的位置)访问元素,并搜索列表中的元素。实现List接口的集合主要有:ArrayList、LinkedList、Vector、Stack。
方法简介:
1 | 1、List集合添加方法 |
ArrayList
简介:ArrayList 是 java 集合框架中比较常用的数据结构了。继承自 AbstractList,实现了 List 接口。底层基于数组实现容量大小动态变化。允许 null 的存在。同时还实现了 RandomAccess、Cloneable、Serializable 接口,所以ArrayList 是支持快速访问、复制、序列化的。
方法简介:
1 | // Collection中定义的API |
注:
- ArrayList 继承了AbstractList,实现了List。它是一个数组队列,提供了相关的添加、删除、修改、遍历等功能。
- ArrayList 实现了RandmoAccess接口,即提供了随机访问功能。RandmoAccess是java中用来被List实现,为List提供快速访问功能的。在ArrayList中,我们即可以通过元素的序号快速获取元素对象;这就是快速随机访问。稍后,我们会比较List的“快速随机访问”和“通过Iterator迭代器访问”的效率。
- ArrayList 实现了Cloneable接口,即覆盖了函数clone(),能被克隆。
- ArrayList 实现java.io.Serializable接口,这意味着ArrayList支持序列化,能通过序列化去传输。
- 和Vector不同,ArrayList中的操作不是线程安全的!所以,建议在单线程中才使用ArrayList,而在多线程中可以选择Vector或者CopyOnWriteArrayList。
- ArrayList 实际上是通过一个数组去保存数据的。当我们构造ArrayList时;若使用默认构造函数,则ArrayList的默认容量大小是10。
- 当ArrayList容量不足以容纳全部元素时,ArrayList会重新设置容量:新的容量=“(原始容量x3)/2 + 1”。
- ArrayList的克隆函数,即是将全部元素克隆到一个数组中。
- ArrayList实现java.io.Serializable的方式。当写入到输出流时,先写入“容量”,再依次写入“每一个元素”;当读出输入流时,先读取“容量”,再依次读取“每一个元素”。
LinkedList
简介:
LinkedList 是一个继承于AbstractSequentialList的双向链表。它也可以被当作堆栈、队列或双端队列进行操作。
LinkedList 实现 List 接口,能对它进行队列操作。
LinkedList 实现 Deque 接口,即能将LinkedList当作双端队列使用。
LinkedList 实现了Cloneable接口,即覆盖了函数clone(),能克隆。
LinkedList 实现java.io.Serializable接口,这意味着LinkedList支持序列化,能通过序列化去传输。
LinkedList 是非同步的。
LinkedList实际上是通过双向链表去实现的。既然是双向链表,那么它的顺序访问会非常高效,而随机访问效率比较低。
既然LinkedList是通过双向链表的,它的每个元素分配的空间不必连续,但是它也实现了List接口{也就是说,它实现了get(int location)、remove(int location)等“根据索引值来获取、删除节点的函数”}。LinkedList是如何实现List的这些接口的,如何将“双向链表和索引值联系起来的”?
实际原理非常简单,它就是通过一个计数索引值来实现的。例如,当我们调用get(int location)时,首先会比较“location”和“双向链表长度的1/2”;若前者大,则从链表头开始往后查找,直到location位置;否则,从链表末尾开始先前查找,直到location位置。
这就是“双线链表和索引值联系起来”的方法。
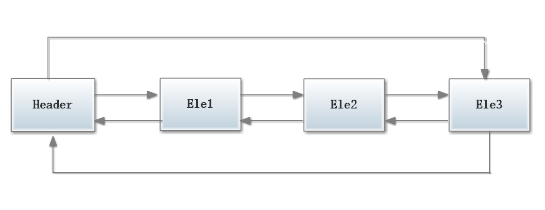
无论LikedList是否为空,链表内部都有一个header表项,它既表示链表的开始,也表示链表的结尾。表项header的后驱表项便是链表中第一个元素,表项header的前驱表项便是链表中最后一个元素。
方法简介:
1 | // 默认构造函数 |
注:
- LinkedList 实际上是通过双向链表去实现的。
- 它包含一个非常重要的内部类:Entry。Entry是双向链表节点所对应的数据结构,它包括的属性有:当前节点所包含的值,上一个节点,下一个节点。
- 从LinkedList的实现方式中可以发现,它不存在LinkedList容量不足的问题。
- LinkedList的克隆函数,即是将全部元素克隆到一个新的LinkedList对象中。
- LinkedList实现java.io.Serializable。当写入到输出流时,先写入“容量”,再依次写入“每一个节点保护的值”;当读出输入流时,先读取“容量”,再依次读取“每一个元素”。
由于LinkedList实现了Deque,而Deque接口定义了在双端队列两端访问元素的方法。提供插入、移除和检查元素的方法。每种方法都存在两种形式:一种形式在操作失败时抛出异常,另一种形式返回一个特殊值(null 或 false,具体取决于操作)。
LinkedList继承于AbstractSequentialList,并且实现了Dequeue接口
- LinkedList包含两个重要的成员:header 和 size。
header是双向链表的表头,它是双向链表节点所对应的类Entry的实例。Entry中包含成员变量: previous, next, element。其中,previous是该节点的上一个节点,next是该节点的下一个节点,element是该节点所包含的值。
size是双向链表中节点的个数。
Vector
简介:
Vector 是矢量队列,它是JDK1.0版本添加的类。继承于AbstractList,实现了List, RandomAccess, Cloneable这些接口。
Vector 继承了AbstractList,实现了List;所以,它是一个队列,支持相关的添加、删除、修改、遍历等功能。
Vector 实现了RandmoAccess接口,即提供了随机访问功能。RandmoAccess是java中用来被List实现,为List提供快速访问功能的。在Vector中,我们即可以通过元素的序号快速获取元素对象;这就是快速随机访问。
Vector 实现了Cloneable接口,即实现clone()函数。它能被克隆。
创建了一个向量类(Vector)的对象后,可以往其中随意插入不同类的对象,即不需顾及类型也不需预先选定向量的容量,并可以方便地进行查找。对于预先不知或者不愿预先定义数组大小,并且需要频繁地进行查找,插入,删除工作的情况。可以考虑使用向量类。
Vector底层的数据存储都使用的Object数组实现
和ArrayList不同,Vector中的操作是线程安全的
方法简介:
1 | Vector共有4个构造函数 |
注:
包含了3个成员变量:elementData , elementCount, capacityIncrement。
elementData 是”Object[]类型的数组”,它保存了添加到Vector中的元素。elementData是个动态数组,如果初始化Vector时,没指定动态数组的大小,则使用默认大小10。随着Vector中元素的增加,Vector的容量也会动态增长,capacityIncrement是与容量增长相关的增长系数,当capacityIncrement等于0时,增长为原来的2倍,否则,每次增长的量为capacityIncrement。
elementCount 是动态数组的实际大小。
Vector的克隆函数,即是将全部元素克隆到一个数组中。
呼呼~ 叹口气。List终于要告一段落了,接下来开始我们的Set之旅吧~
但是在Java中并不推荐使用Vector,原因如下:
1.因为vector是线程安全的,所以效率低,这容易理解,类似StringBuffer
2.Vector空间满了之后,扩容是一倍,而ArrayList仅仅是一半
3.Vector分配内存的时候需要连续的存储空间,如果数据太多,容易分配内存失败
Set接口
简介:一个不包含重复元素的 collection。无序且唯一。
敲重点:
- HashSet
- LinkedHashSet
- TreeSet
方法简介:
Set接口仅包含从Collection继承的方法(所以在这里我就不赘述了,因为我是个懒蛋,略略略~),并添加禁止重复元素
的限制,Set还为equals和hashCode操作的行为添加了一个更强的契约,允许Set实例有意义地进行比较,即使它们的实现
不同,如果两个Set实例包含相同的元素,则它们是相等的。
注:
它使用equals()方法进行比较,如果返回true,两个对象的HashCode值也应该相等。
HashSet
简介:
HashSet是Set接口的典型实现,HashSet按照Hash算法来存储集合中的元素。内部使用HashMap来存储数据,数据存储在HashMap的key中,value都是同一个默认值。HashSet使用成员对象来计算hashcode值,对于两个对象来说hashcode可能相同,所以equals()方法用来判断对象的相等性,如果两个对象不同的话,那么返回false。存在以下特点:
- 不能保证元素的顺序,元素是无序的
- HashSet不是同步的,需要外部保持线程之间的同步问题
- 集合元素值允许为null
1 | --------------------------------------构造方法-------------------------------------- |
添加元素:
注:
- HashSet的底层通过HashMap实现的。而HashMap在1.7之前使用的是数组+链表实现,在1.8+使用的数组+链表+红黑树实现。其实也可以这样理解,HashSet的底层实现和HashMap使用的是相同的方式,因为Map是无序的,因此HashSet也无法保证顺序。
- HashSet的方法,也是借助HashMap的方法来实现的。
小插曲:HashCode方法详解
总的来说,Java中的集合(Collection)有两类,一类是List,再有一类是Set。
你知道它们的区别吗?前者集合内的元素是有序的,元素可以重复;后者元素无序,但元素不可重复。
那么这里就有一个比较严重的问题了:要想保证元素不重复,可两个元素是否重复应该依据什么来判断呢?
这就是Object.equals方法了。但是,如果每增加一个元素就检查一次,那么当元素很多时,后添加到集合中的元素比较的次数就非常多了。 也就是说,如果集合中现在已经有1000个元素,那么第1001个元素加入集合时,它就要调用1000次equals方法。这显然会大大降低效率。
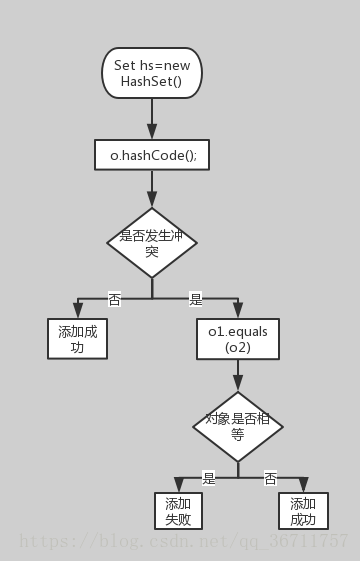
于是,Java采用了哈希表的原理。哈希(Hash)实际上是个人名,由于他提出一哈希算法的概念,所以就以他的名字命名了。 哈希算法也称为散列算法,是将数据依特定算法直接指定到一个地址上。如果详细讲解哈希算法,那需要更多的文章篇幅,我在这里就不介绍了。
初学者可以这样理解,hashCode方法实际上返回的就是对象存储的物理地址(实际可能并不是)。 这样一来,当集合要添加新的元素时,先调用这个元素的hashCode方法,就一下子能定位到它应该放置的物理位置上。 如果这个位置上没有元素,它就可以直接存储在这个位置上,不用再进行任何比较了;如果这个位置上已经有元素了, 就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址。 所以这里存在一个冲突解决的问题。这样一来实际调用equals方法的次数就大大降低了,几乎只需要一两次。 所以,Java对于eqauls方法和hashCode方法是这样规定的:
1、如果两个对象相同,那么它们的hashCode值一定要相同;
2、如果两个对象的hashCode相同,它们并不一定相同 ;
上面说的对象相同指的是用eqauls方法比较。你当然可以不按要求去做了,但你会发现,相同的对象可以出现在Set集合中。同时,增加新元素的效率会大大下降。
hashcode这个方法是用来鉴定2个对象是否相等的。 那你会说,不是还有equals这个方法吗? 不错,这2个方法都是用来判断2个对象是否相等的。但是他们是有区别的。 一般来讲,equals这个方法是给用户调用的,如果你想判断2个对象是否相等,你可以重写equals方法,然后在代码中调用,就可以判断他们是否相等 了。简单来讲,equals方法主要是用来判断从表面上看或者从内容上看,2个对象是不是相等。
举个例子,有个学生类,属性只有姓名和性别,那么我们可以认为只要姓名和性别相等,那么就说这2个对象是相等的。
hashcode方法一般用户不会去调用,比如在hashmap中,由于key是不可以重复的,他在判断key是不是重复的时候就判断了hashcode 这个方法,而且也用到了equals方法。这里不可以重复是说equals和hashcode只要有一个不等就可以了!所以简单来讲,hashcode相当于是一个对象的编码,就好像文件中的md5,他和equals不同就在于他返回的是int型的,比较起来不直观。我们一般在覆盖equals的同时也要 覆盖hashcode,让他们的逻辑一致。
举个例子,还是刚刚的例子,如果姓名和性别相等就算2个对象相等的话,那么hashcode的方法也要返回姓名 的hashcode值加上性别的hashcode值,这样从逻辑上,他们就一致了。 要从物理上判断2个对象是否相等,用==就可以了。
LinkedHashSet
简介:LinkedHashSet集合同样是根据元素的hashCode值来决定元素的存储位置,但是它同时使用链表(双向)维护元素的次序。这样使得元素看起 来像是以插入顺 序保存的,也就是说,当遍历该集合时候,LinkedHashSet将会以元素的添加顺序访问集合的元素。
与HashSet比较:LinkedHashSet在迭代访问Set中的全部元素时,性能比HashSet好,但是插入时性能稍微逊色于HashSet。
方法简介:
1 | public class LinkedHashSet<E> |
注:
LinkedHashSet通过继承HashSet,底层使用LinkedHashMap,以很简单明了的方式来实现了其自身的所有功能。
TreeSet
简介:TreeSet类型是J2SE中唯一可实现自动排序的类型
TreeSet是SortedSet接口的唯一实现类,TreeSet可以确保集合元素处于排序状态。TreeSet支持两种排序方式,自然排序 和定制排序,其中自然排序为默认的排序方式。向 TreeSet中加入的应该是同一个类的对象。
TreeSet判断两个对象不相等的方式是两个对象通过equals方法返回false,或者通过CompareTo方法比较没有返回0
自然排序
自然排序使用要排序元素的CompareTo(Object obj)方法来比较元素之间大小关系,然后将元素按照升序排列。
Java提供了一个Comparable接口,该接口里定义了一个compareTo(Object obj)方法,该方法返回一个整数值,实现了该接口的对象就可以比较大小。
obj1.compareTo(obj2)方法如果返回0,则说明被比较的两个对象相等,如果返回一个正数,则表明obj1大于obj2,如果是 负数,则表明obj1小于obj2。
如果我们将两个对象的equals方法总是返回true,则这两个对象的compareTo方法返回应该返回0
定制排序
自然排序是根据集合元素的大小,以升序排列,如果要定制排序,应该使用Comparator接口,实现 int compare(To1,To2)方法
方法简介:
1 | ---------------------------构造方法------------------------------------------------- |
注:
- TreeSet实现SortedSet接口,因此不允许重复值。
- TreeSet中的对象按排序和升序存储。
- TreeSet不保留元素的插入顺序,但元素按键排序。
- TreeSet不允许插入异类对象。如果尝试添加hetrogeneous对象,它将在运行时抛出classCastException。
- TreeSet是存储大量已排序信息的绝佳选择,因为它可以更快地访问和检索,因此可以快速访问这些信息。
- TreeSet基本上是像Red-Black Tree这样的自平衡二叉搜索树的实现。因此,添加,删除和搜索等操作需要O(Log n)时间。并且按排序顺序打印n个元素的操作需要O(n)时间。
EnumSet
写在前面:了解即可====
为什么要有EnumSet?
EnumSet是Java枚举类型的泛型容器,Java既然有了SortedSet、TreeSet、HashSet等容器,为何还要多一个EnumSet
首先以事实说话,存在这样一个EnumSet,它有50个枚举值T0~T49,将50个值插入到容器(HashSet、EnumSet)中,为一个操作,将50个枚举值移出做为第二个操作。把第一个和第二个操作执行的总时间设定为一个周期,拿HashSet操作的一个周期和EnumSet的一个周期做比较自然没什么意义,所以我们用50个周期的和做为比较,HashSet耗费9ms,EnumSet耗费4ms。
简介:EnumSet 是一个专为枚举设计的集合类,EnumSet中的所有元素都必须是指定枚举类型的枚举值,该枚举类型在创建EnumSet时显式或隐式地指定。
方法简介:
1 | EnumSet allOf(Class elementType): 创建一个包含指定枚举类里所有枚举值的EnumSet集合。 |
注:
- EnumSet的集合元素也是有序的,EnumSet以枚举值在Enum类内的定义顺序来决定集合元素的顺序。
- EnumSet在内部以位向量的形式存储,这种存储形式非常紧凑、高效,因此EnumSet对象占用内存很小,而且运行效率很好。尤其是进行批量操作(如调用containsAll()和retainAll()方法)时,如果其参数也是EnumSet集合,则该批量操作的执行速度也非常快。
- EnumSet集合不允许加入null元素,如果试图插入null元素,EnumSet将抛出NullPointerException异常。
- EnumSet类没有暴露任何构造器来创建该类的实例,程序应该通过它提供的类方法来创建EnumSet对象。
- 如果只是想判断EnumSet是否包含null元素或试图删除null元素都不会抛出异常,只是删除操作将返回false,因为没有任何null元素被删除。
Queue
简介:基本上,一个队列就是一个先入先出(FIFO)的数据结构
Queue接口与List、Set同一级别,都是继承了Collection接口。LinkedList实现了Deque接 口。
在java5中新增加了java.util.Queue接口,用以支持队列的常见操作。该接口扩展了java.util.Collection接口。
Queue使用时要尽量避免Collection的add()和remove()方法,而是要使用offer()来加入元素,使用poll()来获取并移出元素。它们的优点是通过返回值可以判断成功与否,add()和remove()方法在失败的时候会抛出异常。 如果要使用前端而不移出该元素,使用element()或者peek()方法。
值得注意的是LinkedList类实现了Queue接口,因此我们可以把LinkedList当成Queue来用。
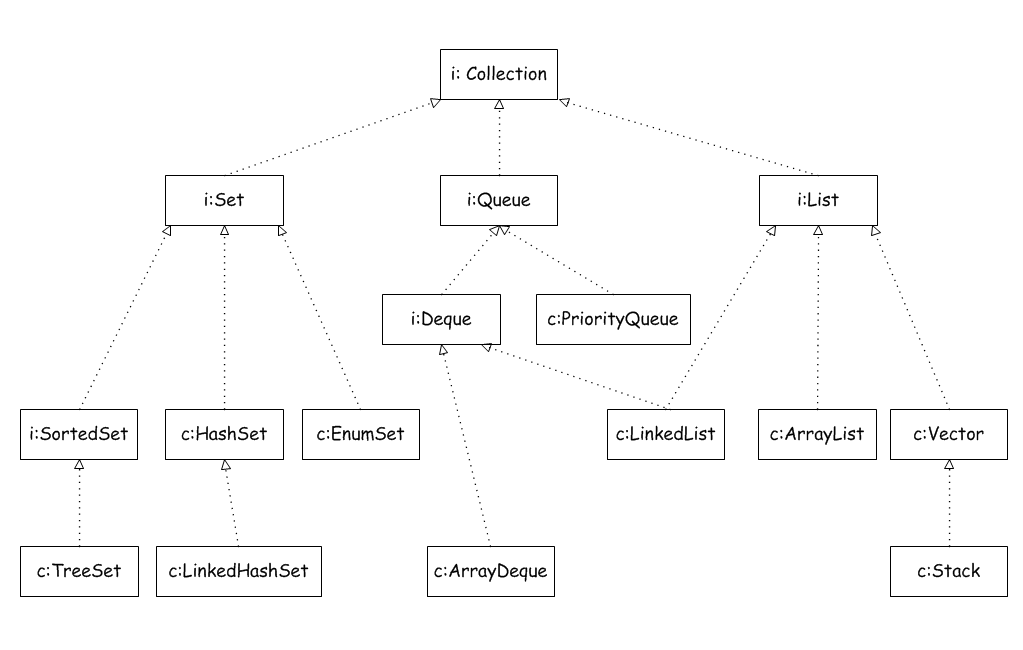
Queue结构关系:
内置的不阻塞队列: PriorityQueue 和 ConcurrentLinkedQueue
PriorityQueue 和 ConcurrentLinkedQueue 类在 Collection Framework 中加入两个具体集合实现。
PriorityQueue 类实质上维护了一个有序列表。加入到 Queue 中的元素根据它们的天然排序(通过其 java.util.Comparable 实现)或者根据传递给构造函数的 java.util.Comparator 实现来定位。
ConcurrentLinkedQueue 是基于链接节点的、线程安全的队列。并发访问不需要同步。因为它在队列的尾部添加元素并从头部删除它们,所以只要不需要知道队列的大 小,ConcurrentLinkedQueue 对公共集合的共享访问就可以工作得很好。收集关于队列大小的信息会很慢,需要遍历队列。
java.util.concurrent 中加入了 BlockingQueue 接口和五个阻塞队列类。
它实质上就是一种带有一点扭曲的 FIFO 数据结构。不是立即从队列中添加或者删除元素,线程执行操作阻塞,直到有空间或者元素可用。
五个队列所提供的各有不同:
- ArrayBlockingQueue :一个由数组支持的有界队列。
- LinkedBlockingQueue :一个由链接节点支持的可选有界队列。
- PriorityBlockingQueue :一个由优先级堆支持的无界优先级队列。
- DelayQueue :一个由优先级堆支持的、基于时间的调度队列。
- SynchronousQueue :一个利用 BlockingQueue 接口的简单聚集(rendezvous)机制。
LinkedBlockingQueue的容量是没有上限的(说的不准确,在不指定时容量为Integer.MAX_VALUE,不要然的话在put时怎么会受阻呢),但是也可以选择指定其最大容量,它是基于链表的队列,此队列按 FIFO(先进先出)排序元素。
ArrayBlockingQueue在构造时需要指定容量, 并可以选择是否需要公平性,如果公平参数被设置true,等待时间最长的线程会优先得到处理(其实就是通过将ReentrantLock设置为true来 达到这种公平性的:即等待时间最长的线程会先操作)。通常,公平性会使你在性能上付出代价,只有在的确非常需要的时候再使用它。它是基于数组的阻塞循环队 列,此队列按 FIFO(先进先出)原则对元素进行排序。
PriorityBlockingQueue是一个带优先级的 队列,而不是先进先出队列。元素按优先级顺序被移除,该队列也没有上限(看了一下源码,PriorityBlockingQueue是对 PriorityQueue的再次包装,是基于堆数据结构的,而PriorityQueue是没有容量限制的,与ArrayList一样,所以在优先阻塞 队列上put时是不会受阻的。虽然此队列逻辑上是无界的,但是由于资源被耗尽,所以试图执行添加操作可能会导致 OutOfMemoryError),但是如果队列为空,那么取元素的操作take就会阻塞,所以它的检索操作take是受阻的。另外,往入该队列中的元 素要具有比较能力。
DelayQueue(基于PriorityQueue来实现的)是一个存放Delayed 元素的无界阻塞队列,只有在延迟期满时才能从中提取元素。该队列的头部是延迟期满后保存时间最长的 Delayed 元素。如果延迟都还没有期满,则队列没有头部,并且poll将返回null。当一个元素的 getDelay(TimeUnit.NANOSECONDS) 方法返回一个小于或等于零的值时,则出现期满,poll就以移除这个元素了。此队列不允许使用 null 元素。
相关方法:
1 | //jdk1.5中的阻塞队列的操作: |
Map
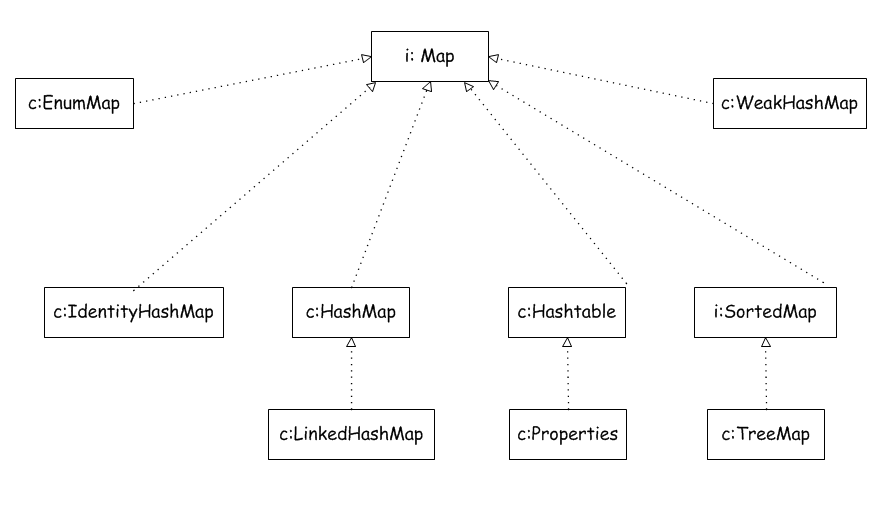
Map接口
简介:Map接口储存一组成对的键-值对象,提供key(键)到value(值)的映射,Map中的key不要求有序,不允许重复。value同样不要求有序,但可以重复。
方法简介:
1 | void clear( ) |
注:
- Map提供了一种映射关系,其中的元素是以键值对(key-value)的形式存储的,能够实现根据key快速查找value;
- Map中的键值对以Entry类型的对象实例形式存在;
- 建(key值)不可重复,value值可以重复,一个value值可以和很多key值形成对应关系,每个建最多只能映射到一个值。
- Map支持泛型,形式如:Map<K,V>
- Map中使用put(K key,V value)方法添加
HashMap
写在前面:HashMap灰常重要,别怪我没提醒你呦~~~
简介:
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
HashMap 的实现不是同步的,这意味着它不是线程安全的。它的key、value都可以为null。此外,HashMap中的映射不是有序的。
细说一下吧:HashMap 的实例有两个参数影响其性能:“初始容量” 和 “加载因子”。容量 是哈希表中桶的数量,初始容量 只是哈希表在创建时的容量。加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
通常,默认容量是16,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查询成本(在大多数 HashMap 类的操作中,包括 get 和 put 操作,都反映了这一点)。在设置初始容量时应该考虑到映射中所需的条目数及其加载因子,以便最大限度地减少 rehash 操作次数。如果初始容量大于最大条目数除以加载因子,则不会发生 rehash 操作。
相比其他几种数据结构,在哈希表中进行添加,删除,查找等操作,性能十分之高,不考虑哈希冲突的情况下,仅需一次定位即可完成,时间复杂度为O(1)。通过哈希函数一次定位到存储位置。
哈希冲突/哈希碰撞:对多个元素进行哈希运算得到同样的存储地址。
哈希冲突的解决方案有多种:开放定址法(发生冲突,继续寻找下一块未被占用的存储地址),再散列函数法,链地址法,而HashMap即是采用了链地址法,也就是数组+链表的方式
方法简介:
1 | ---------------------------构造方法------------------------------------------------ |
既然他重要,咱们就多废话两句,看看他的结构关系吧
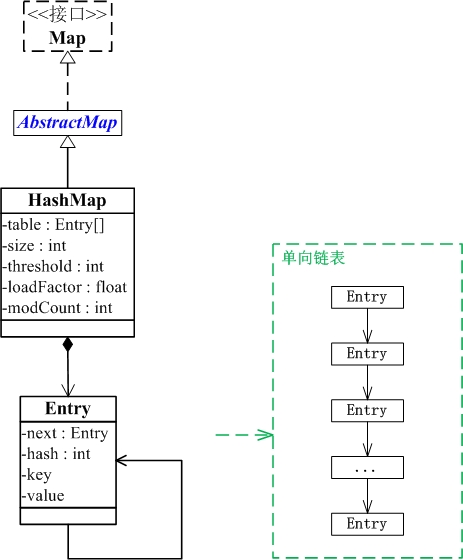
说明:
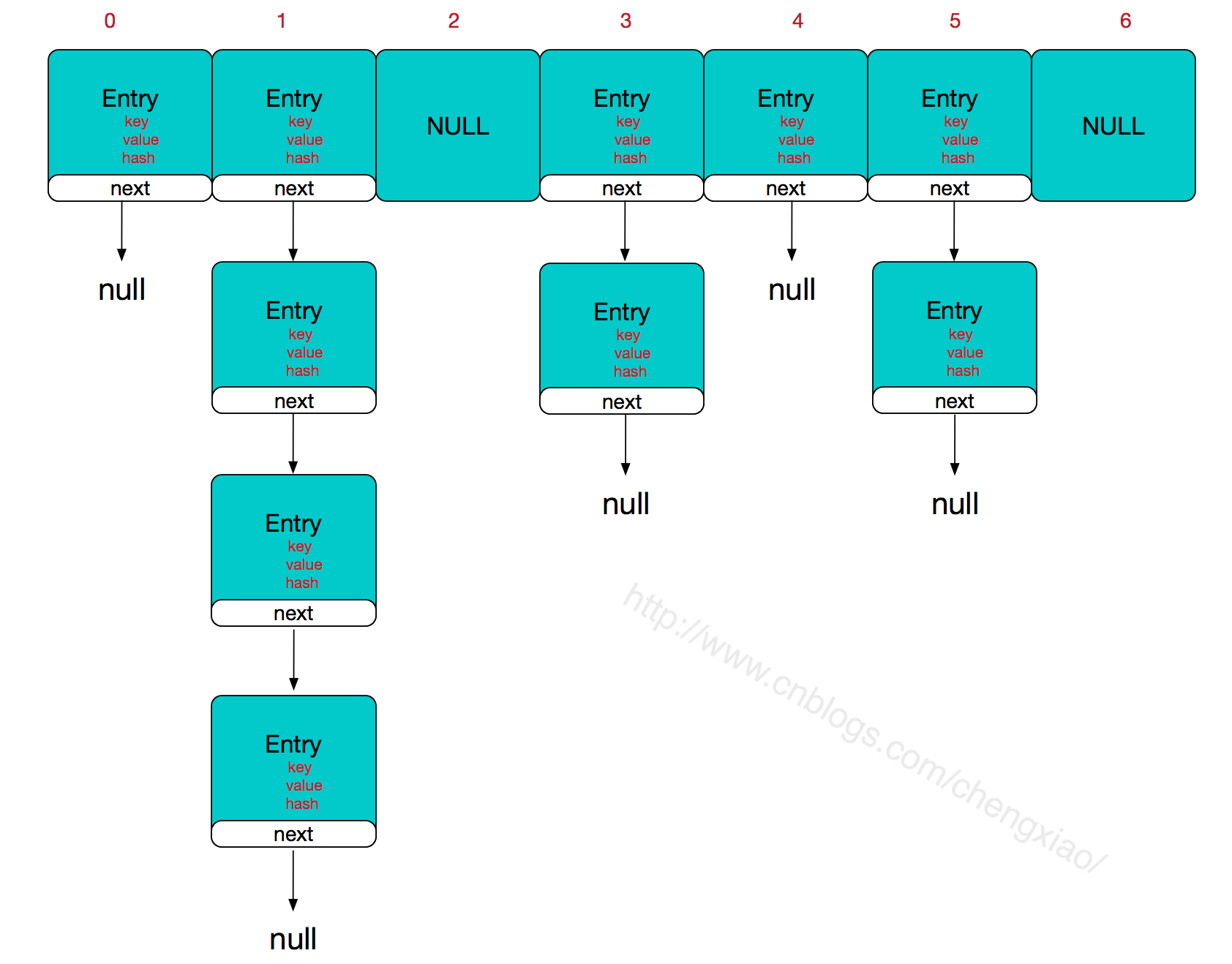
简单来说,HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么对于查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增;对于查找操作来讲,仍需遍历链表,然后通过key对象的equals方法逐一比对查找。所以,性能考虑,HashMap中的链表出现越少,性能才会越好。
HashMap继承于AbstractMap类,实现了Map接口。Map是”key-value键值对”接口,AbstractMap实现了”键值对”的通用函数接口。
HashMap是通过”拉链法”实现的哈希表。它包括几个重要的成员变量:table, size, threshold, loadFactor, modCount。
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的”key-value键值对”都是存储在Entry数组中的。
size是HashMap的大小,它是HashMap保存的键值对的数量。
threshold是HashMap的阈值,用于判断是否需要调整HashMap的容量。threshold的值=”容量*加载因子”,当HashMap中存储数据的数量达到threshold时,就需要将HashMap的容量加倍。
loadFactor就是加载因子。
modCount是用来实现fail-fast机制的
HashTable
简介:
和HashMap一样,Hashtable 也是一个散列表,它存储的内容是键值对(key-value)映射。
Hashtable 继承于Dictionary,实现了Map、Cloneable、java.io.Serializable接口。
Hashtable 的函数都是同步的,这意味着它是线程安全的。它的key、value都不可以为null。此外,Hashtable中的映射不是有序的。
Hashtable 的实例有两个参数影响其性能:初始容量 和 加载因子。容量 是哈希表中桶 的数量,初始容量 就是哈希表创建时的容量。注意,哈希表的状态为 open:在发生“哈希冲突”的情况下,单个桶会存储多个条目,这些条目必须按顺序搜索。加载因子 是对哈希表在其容量自动增加之前可以达到多满的一个尺度。初始容量和加载因子这两个参数只是对该实现的提示。关于何时以及是否调用 rehash 方法的具体细节则依赖于该实现。
通常,默认加载因子是 0.75, 这是在时间和空间成本上寻求一种折衷。加载因子过高虽然减少了空间开销,但同时也增加了查找某个条目的时间(在大多数 Hashtable 操作中,包括 get 和 put 操作,都反映了这一点)
方法简介:
1 | -------------------------------构造函数---------------------------------- |
结构图:
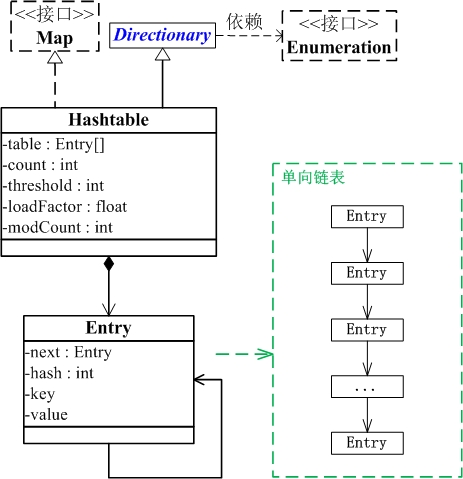
说明:
Hashtable继承于Dictionary类,实现了Map接口。Map是”key-value键值对”接口,Dictionary是声明了操作”键值对”函数接口的抽象类。
Hashtable是通过”拉链法”实现的哈希表。它包括几个重要的成员变量:table, count, threshold, loadFactor, modCount。
table是一个Entry[]数组类型,而Entry实际上就是一个单向链表。哈希表的”key-value键值对”都是存储在Entry数组中的。
count是Hashtable的大小,它是Hashtable保存的键值对的数量。
threshold是Hashtable的阈值,用于判断是否需要调整Hashtable的容量。threshold的值=”容量*加载因子”。
loadFactor就是加载因子。
modCount是用来实现fail-fast机制的
TreeMap
简介:TreeMap可以实现存储元素的自动排序。在TreeMap中,键值对之间按键有序,TreeMap的实现基础是红黑树。
方法简介:
1 | ----------------------------构造方法-------------------------------------- |
注:
- TreeMap 是一个有序的key-value集合,它是通过红黑树实现的。
- TreeMap 继承于AbstractMap,所以它是一个Map,即一个key-value集合。
- TreeMap 实现了NavigableMap接口,意味着它支持一系列的导航方法。比如返回有序的key集合。
- TreeMap 实现了Cloneable接口,意味着它能被克隆。
- TreeMap 实现了java.io.Serializable接口,意味着它支持序列化。
- TreeMap基于红黑树(Red-Black tree)实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
- TreeMap的基本操作 containsKey、get、put 和 remove 的时间复杂度是 log(n) 。
- 另外,TreeMap是非同步的。 它的iterator 方法返回的迭代器是fail-fastl的。
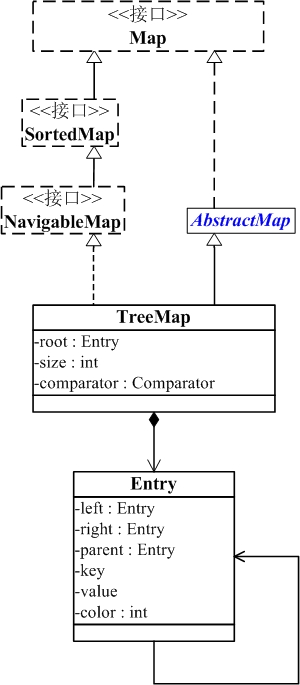
说明:
TreeMap实现继承于AbstractMap,并且实现了NavigableMap接口。
TreeMap的本质是R-B Tree(红黑树),它包含几个重要的成员变量: root, size, comparator。
root 是红黑数的根节点。它是Entry类型,Entry是红黑数的节点,它包含了红黑数的6个基本组成成分:key(键)、value(值)、left(左孩子)、right(右孩子)、parent(父节点)、color(颜色)。Entry节点根据key进行排序,Entry节点包含的内容为value。
红黑数排序时,根据Entry中的key进行排序;Entry中的key比较大小是根据比较器comparator来进行判断的。
size是红黑数中节点的个数。
想进一步研究,见Tree Map工作原理